
Abstract
Abstract
Understanding and reasoning about physics is an important ability of intelligent agents. PHYRE is a benchmark for physical reasoning that contains a set of simple classical mechanics puzzles in a 2D enviroment. The benchmark is designed to encourage development of sample-efficient learning algorithms that generalize well across puzzles.
Citation
Citation
Please consider citing the PHYRE paper using the following:
inproceedings{bakhtin2019phyre,
title={PHYRE: A New Benchmark for
Physical Reasoning},
author={Anton Bakhtin and
Laurens van der Maaten and
Justin Johnson and
Laura Gustafson and
Ross Girshick},
year = {2019},
journal={arXiv:1908.05656}
}
Installation Script
Installation Script
More detailed installation instructions on Github.
conda create -n phyre python=3.6;
conda activate phyre;
pip install phyre;
Tasks
Overview
Overview
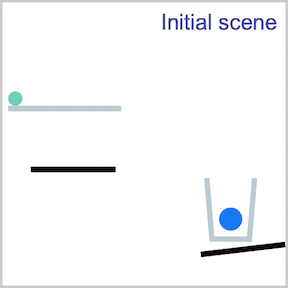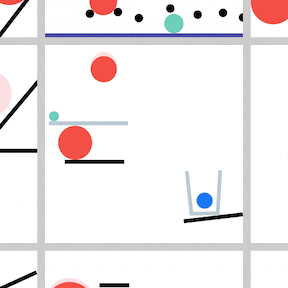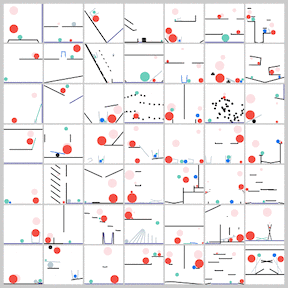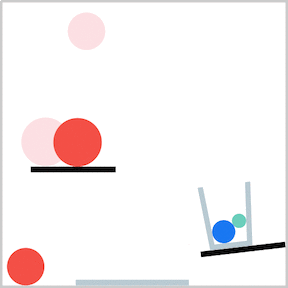
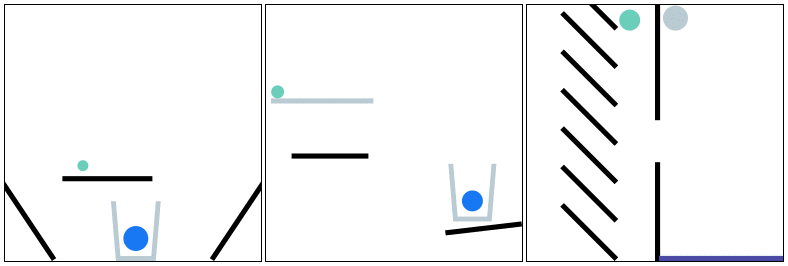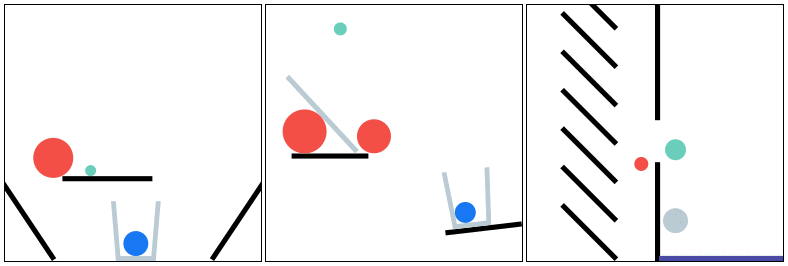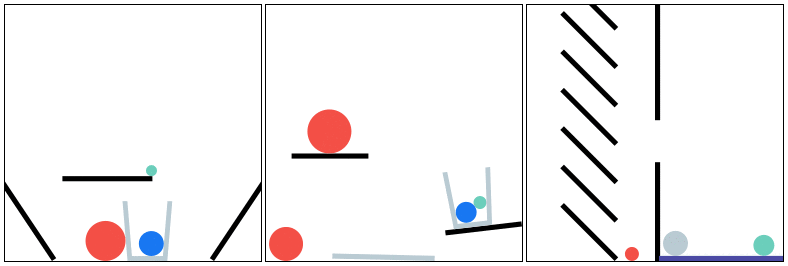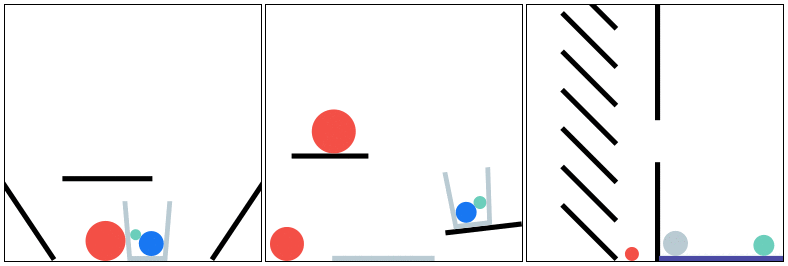
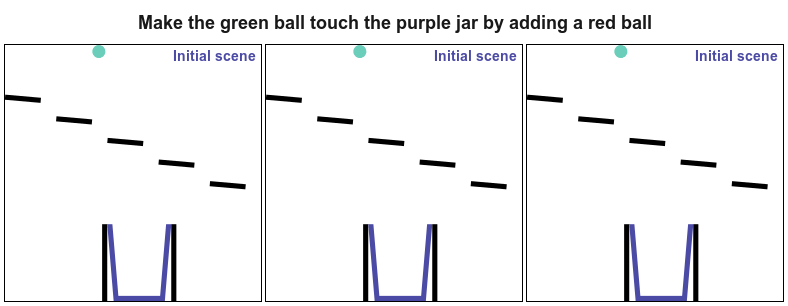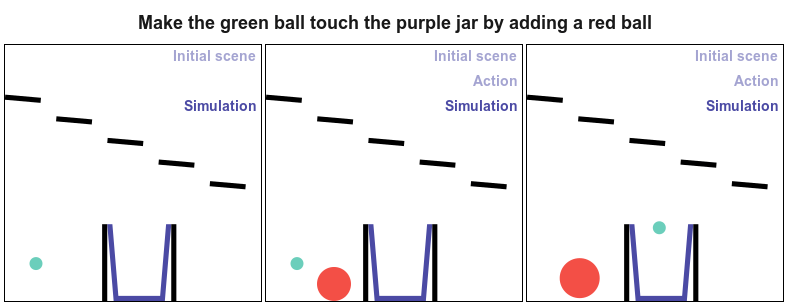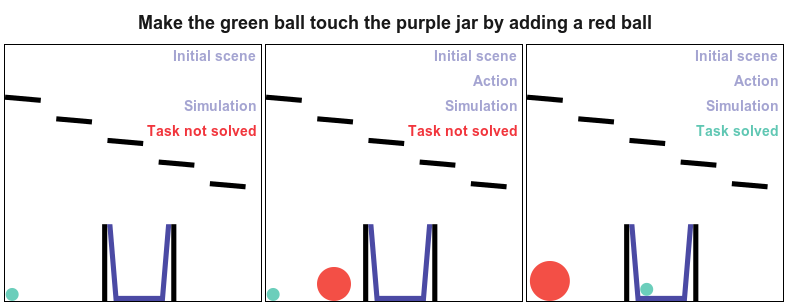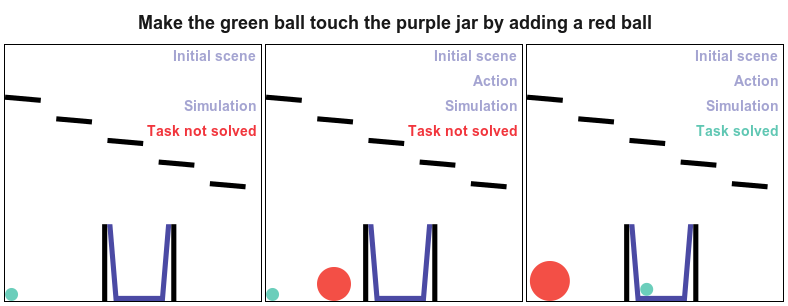
PHYRE provides a set of physics puzzles in a simulated 2D world. Each puzzle has a goal state (e.g., make the green ball touch the blue ball) and an initial state in which the goal is not satisfied; A puzzle can be solved by placing one or more new bodies in the environment such that when the physical simulation is run the goal is satisfied.
Goal
Goal
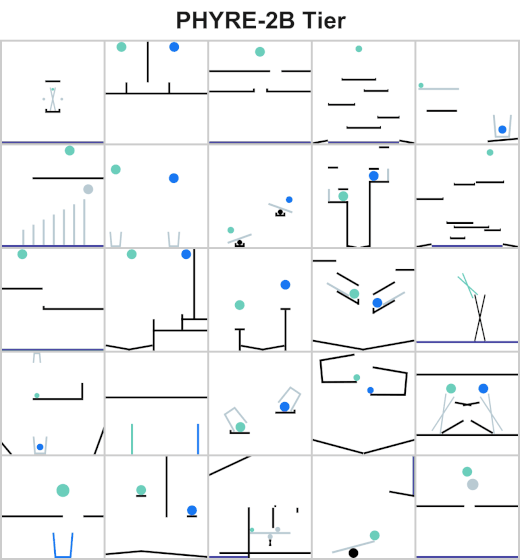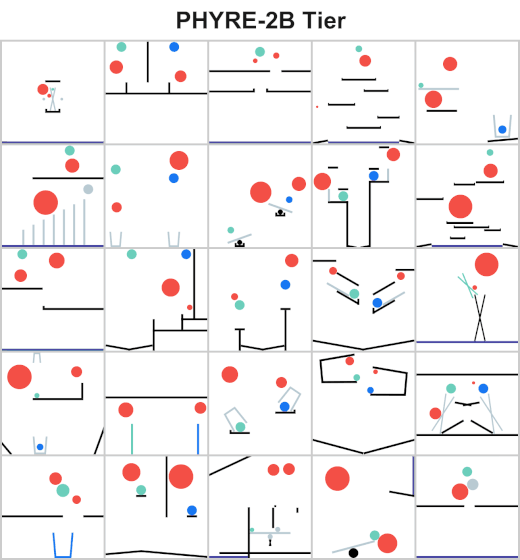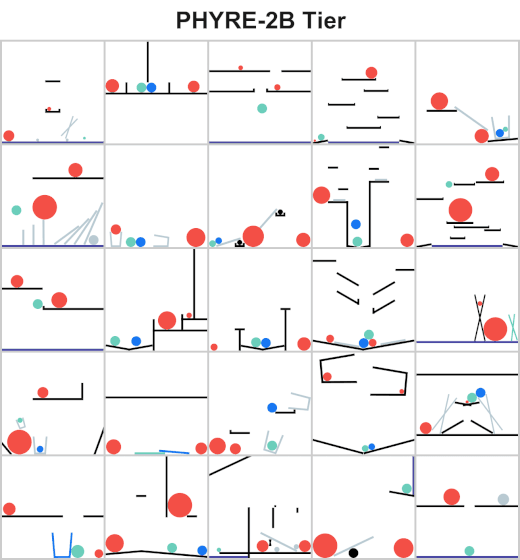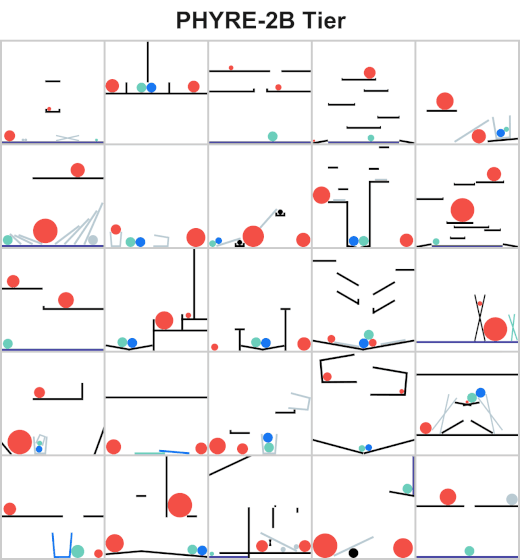
The goal for all tasks within PHYRE is the same: at the end of the simulation the green object must touch the blue or purple object. Agents take actions by placing red objects within the scene to achieve the goal. In PHYRE, each color corresponds to a type of object: red corresponds to user-added dynamic objects, green and blue represent goal dynamic objects, and purple corresponds to a static goal object. Grey corresponds to dynamic scene objects, and black to static scene objects.
Templates
Templates
PHYRE is comprised of a series of task templates, where a task template defines a set of related tasks that are generated by varying task template parameters (such as positions of initial world bodies). All tasks in the same template share a common goal, but have different initial world states. Each template defines 100 such tasks, and belongs to a tier based on the action space of actions required to solve the tasks. Task templates are used to measure an agent’s generalization ability in two settings:
Within-template: an agent trains on a subset of tasks in the template and is evaluated on the remaining tasks within that template.
Cross-template: an agent trains on tasks in a series of templates and test tasks are selected exclusively from templates that were not used for training.
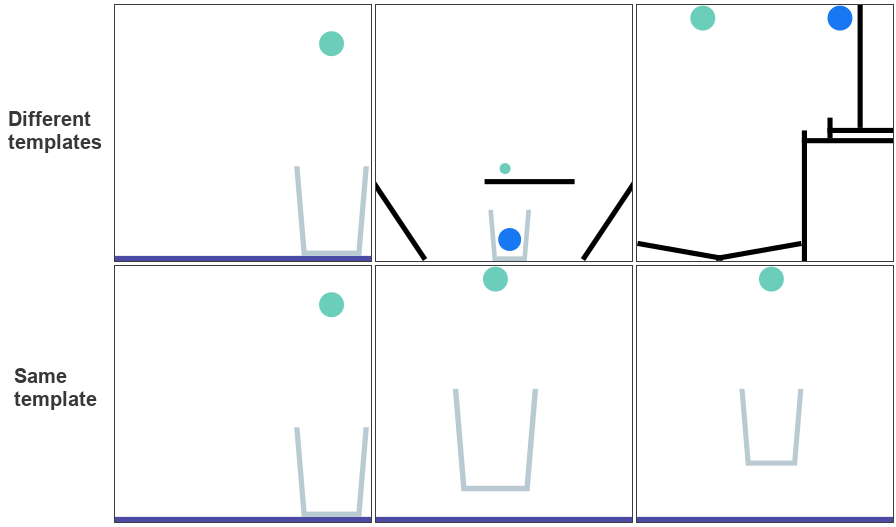
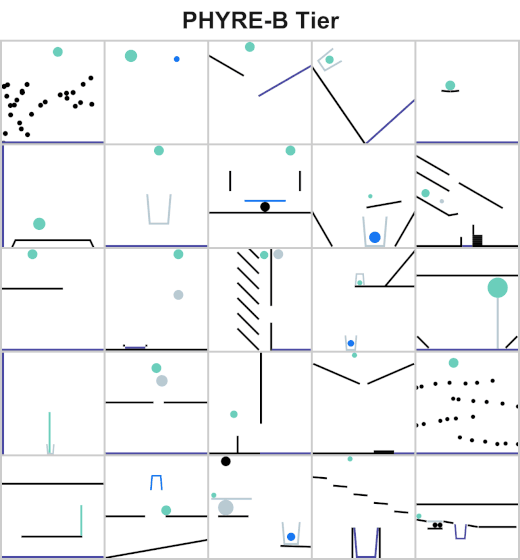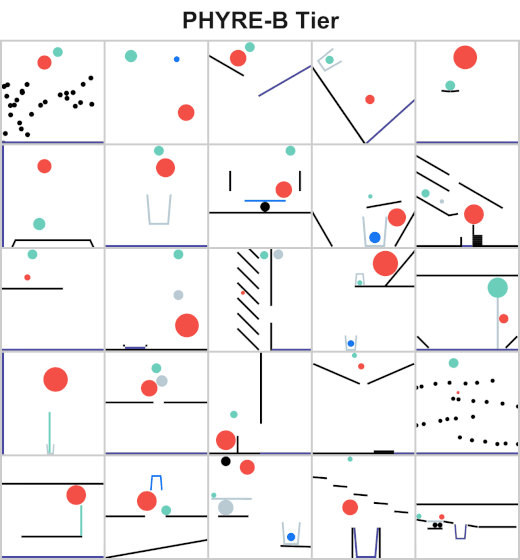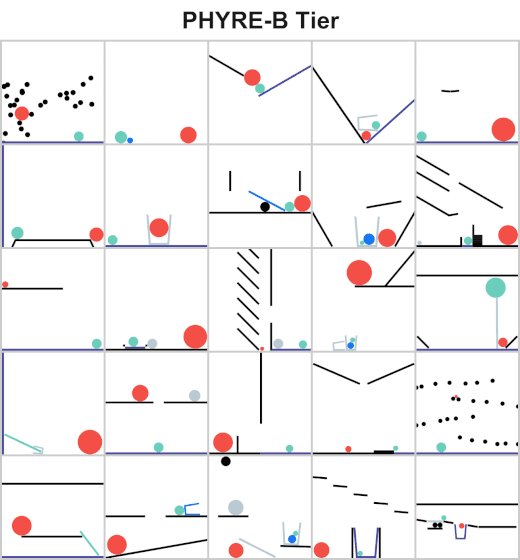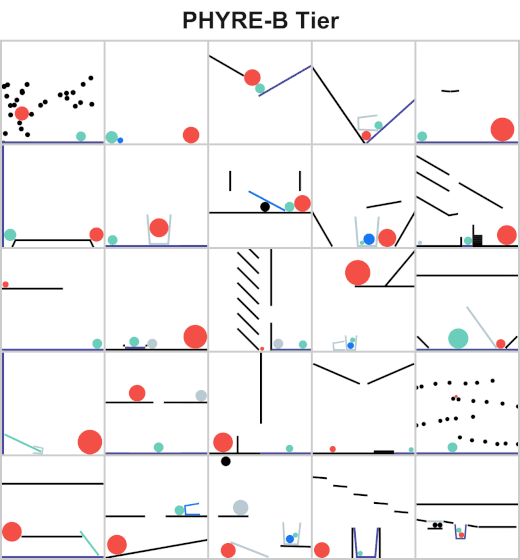
Action space includes all valid locations and radii of a single ball.
Action space includes all valid locations and radii of two balls.